
Challenges to implementing data architecture with packaged applications can be overcome by addressing issues and challenges during design
Introduction
In a previous article I discussed some issues that a client encountered when trying to implement a packaged application. They were convinced that the business would make the decisions and IT was not going to interfere in their packaged implementation. There was a mistaken impression that the increased usage of packaged applications means a decreased role of data architecture.
There are many challenges to implementing packaged applications, especially if the organization does not include data architecture as part of its analysis, design, and implementation. It is a mistake to think that because we are implementing packages we no longer need to be worried about data architecture or design. We are focusing on package applications but these same principles apply to applications developed in-house. A solid enterprise architecture is crucial in a packaged or in-house developed application environment. When basic data governance rules are ignored, mistakes happen that will affect a company for years.
Without a defined strategy, packaged applications will create silos of data. The data will not be easily shareable between applications. Each department has a natural tendency to set-up a package in the way that makes the most sense for their department without being completely aware of the ramifications of their decisions. Viewing all data as an enterprise resource ensures that the data will be shareable across systems. When decisions are being made in the configuration of the accounts receivable package it is critical that it is clearly understood how those decisions will affect the customer service system. We must keep in mind that each data source is one piece of a larger puzzle. We must ensure that each new piece fits in with the existing pieces.
This article will address guideline 2: defining business attributes that cross packages as close to the system of record as possible. A previous article lists all the guidelines and a short description of each.
Many data attributes will appear in multiple software packages as well as internally developed legacy systems. Unless the packages are created by the same software company, and are designed to work together, it is unlikely that the logical and physical properties of the attributes (metadata) will be consistent. It is amazing how sometimes packages designed by the same company are not compatible.
For example (see diagram 1) most organizations have a unique identifier to represent an individual customer or account. In the purchased ABC Accounting System they call the identifier Account-Nr and define it as a 12 byte character field. It is defined as a 12 digit numeric field in the in-house developed data warehouse and in the Account Marketing and Fulfillment package it is defined as a 9 digit number. If we let each of these systems come up with their own account assignment process we will be in trouble. How will they communicate? How can the fulfillment package store a 12 byte character field?
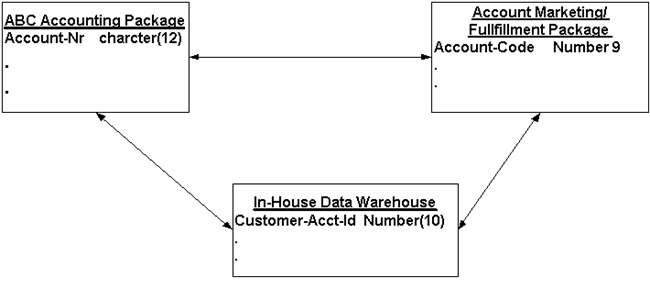
Diagram 1
The first thing we must do is pick a system of record (see the previous issue). In this case new accounts are added within the fulfillment system. This makes this system the logic choice to be the system of record. The business decided that they will assign 9 byte numeric account numbers. When we configure the accounting system we should add edits to the account number to only allow numbers and limit the length to 9 characters. Even though the accounting package allows 12 alphanumeric characters we should make it appear to the business that it is a 9-digit number. We should record in the metadata repository that each of these columns actually represents the same business attribute.
When we assign statuses and other codes it is a good idea to assign them as numeric sequentially assigned numbers. A small number is the most likely shareable data type. A character field can hold a number but a number field cannot hold a character. Another benefit of using numeric code values is it discourages embedding meaning in the code value (a topic for another article).
Customer addresses are another area where we should be very careful. If multiple packages each store a customer address, we have extra issues we must consider. If we have created a table to hold account addresses everyone should use that table whenever possible (see diagram 2). For each customer an address is only stored once. This will enable all areas to benefit from customer feedback to other departments. If the billing department is informed of a change of address and updates the database customer service will automatically have access to the new address.
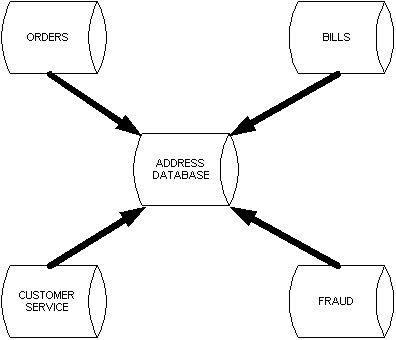
Diagram 2
Now let’s assume that the Fraud department replaces their in-house developed system with a purchased package. The package cannot communicate with the corporate data store. (see diagram 3). If we are not careful, this separate address table could cause many headaches. If customer service receives a change of address, how will the Fraud department know about it? This could cause correspondence to be mistakenly sent to an old address. What if a customer contacts the Fraud department with an address change? How will Customer Service know about it?
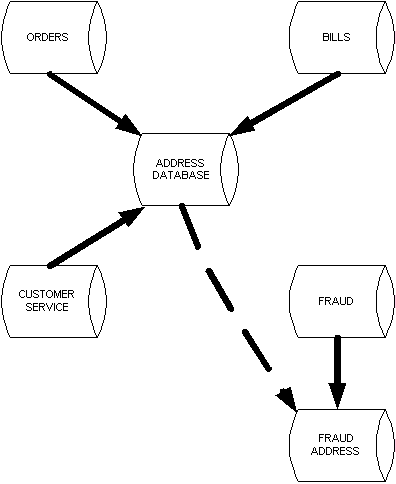
Diagram 3
When we are implementing our Fraud package there are some things we must consider. First, we should define the fraud addresses as close to the format of the system of record as possible. This will enable us to feed changes from the source system to the fraud system. If the Fraud system allows longer length address lines or formats the address differently, then the source system compatibility problems will arise.
Conclusion
This may seem like a lot of work but in the end it will be worth the effort. It is critical that we make the data as shareable as possible. This is also an example of why a good metadata repository is critical to managing any corporate data environment. Within the metadata repository the source system (system of record) should be clearly identified along with and default storage types. We may never reach the ideal world but remember the words of the legendary Green Bay Packers coach Vince Lombardi “Perfection is not attainable, but if we chase perfection we can catch excellence.”

