
Metadata infrastructure planning should start by focusing on the “big picture”, which is the objective of the metadata program, and plan all the MME layers to maintain focus on the objective.
Introduction
When planning to implement a Managed Metadata Environment (MME) infrastructure, it is important to maintain perspective overall objective of the MME program and the fact that all the users will eventually become subscribers of the MME. While the more popular topics (Total Cost of Ownership (TCO), Return on Investment (ROI), Key Performance Indicators (KPI), etc.) could be the focus, little attention is paid to the layers from a physical aspect of planning the infrastructure and to the various layers of the environment.
Metadata management is a program and not a project, a difference that must be acknowledged to plan the infrastructure of this MME program properly. First, it is a program, and not a project that will become a program sometime in the future. Beginning the effort as a program enables the organization to develop the approach to sell the program to executive management to garner the support required to achieve success and gain access to the resources required to allow the program to thrive. Typically, programs are funded out of different budget areas from projects, since they are ongoing and tend to grow in number of users that depend on the services provided by the program.
In most organizations, projects have life cycles with some limited time period, which allows for consultants, contractors, or vendor engineers to help bring the system online more rapidly. With projects that become programs, many organizations make a transition to a more permanent contract-to-hire and full time employee (FTE) staff as the project moves to program mode. These changes may happen with a certain amount of overlap, so that the program staff gets the benefit of mentoring and training from the more knowledgeable personnel that are present during the project portion. Also, the project team is aware of the decision processes made during the planning stages, so that they can communicate the reasons for certain policies and procedures after the permanent staff take over the daily operation of the program.
Walk the Layers
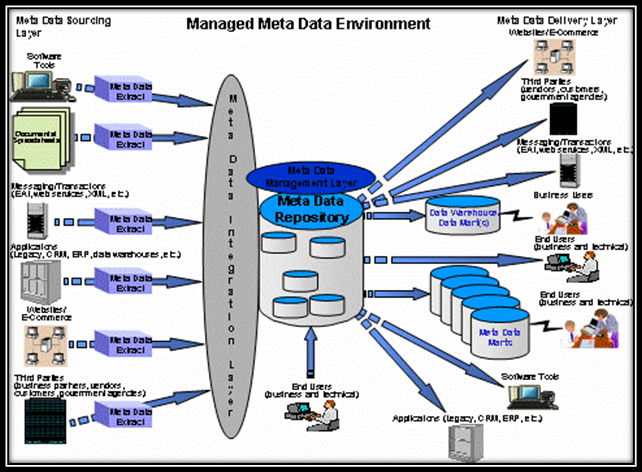
Figure 1: Managed Metadata Environment (MME)
Six layers comprise the MME infrastructure. This article will cover the sourcing and integration layers of the MME. Sourcing will examine the various source types that contribute to the enterprise landscape inventory. The available tools for the collection of sources will govern the inventory structure and the naming conventions needed to identify the content uniquely. Generally, try to sort the content by type, Business and Technical, then by source type such as RDBMS, CASE, ETL, and BI.
The integration layer will bring most of the business content into the repository and integrate it with the technical metadata. Usually employing some rationalized form or standard such as Common Warehouse Metamodel (CWM) or Information Management Metamodel (IMM), most of the integration or rationalization is done in support of business language queries of the repository.
An example could be a query to find all the member sources (mmbr, membrs, etc) that have some specific attribution (eye color, hair color, etc) and have links to a provider source (hospital, clinic, urgent care, etc) that is part of a product scheduled for termination (expiration date, retired date, etc). The integration layer is the most complex, since it involves connections to multiple sources for organizing the metadata from each source.
Plan the Conventions
The naming convention for the MME infrastructure should provide several things to the team utilizing the files regularly. They must name a file uniquely and provide traceability to the environment, source, type, and a date-time stamp if versioning is implemented. While most of the time hierarchy is based on file structures allowing for shorter naming standards, it should be noted that each file will move around the environment in support of load process and, therefore, must be capable of existing in a single directory or folder at any given moment. Thus, the naming conventions should be able to reflect this needed flexibility.
Consider using the naming convention not only for the files created by tools, but also the files, structures and roles used to define specific aspects of the environment. Obviously, one must ascertain the lowest common denominator for name length and consider that while constructing any naming standard.
Consider the platforms involved in the MME and examine any possible transfer of files across those platforms. Mainframes generally are limited to 8 characters per node and some number of nodes per partition data set, while UNIX and Windows are mostly 255 characters per file name and full path. While this seems like a lot of space, long path names can contribute greatly to the consumption of 255 characters. A good naming convention will provide traceability back across platforms, such as the 8-character mainframe name embedded into the 30-40 character UNIX or windows filename.
Plan to group like files together in the environment to make management of the environment easier for the personnel responsible for daily operations. In most of the MME implementations the author has been associated with, the file counts have reached well into the thousands just for sourcing batch, logs, and output. Adding to this volume are the files generated to load the sources into the repository databases, which usually serve different perspectives on the sources like business projects and technical change control analysis.
Sourcing Layer
Consider all functions that must be represented in the files that scan the sources, like environments (development, test, production), location of execution (local, server), type of scan (interactive, batch), as well as content (database, server). If versioning is required for all generated content, be sure to work that point into the naming and file structures. Many metadata technical professionals prefer maintaining current state only, since this simplifies the management greatly and reduces the complexity of the automation processes.
Automation of the sourcing process involves many aspects of data governance and the stewards that are responsible for the enforcement of data policies. In short, data governance should control the MME program, especially for business metadata. Technical metadata is under the purview of the IT group, but the data stewardship team must be able to access it to understand the instantiation of their business requirements.
The data stewards should provide the appropriate feedback to the acquisition developer to aide in setting frequency, execution time of day, and feedback loops for resolution for issues that will surface over time with automated processes. Automation within a single platform is difficult; adding multiple platforms, scanner source dependencies and load balancing will make for some extremely complex job streams. Processing thousands of source systems in a given time over a specific window of operational access is a normal function for a fully functioning MME.
Consider also that the scanning of sources is only the first part of the process and the load(s) will be carried out during non-business hours, typically, to minimize the negative impact on performance in the users’ views. Generally, the users will start by requesting daily refreshes. However, this is not achievable in most circumstances since there can be hundreds or thousands of sources to process. Dividing sources into tiers of importance with revenue systems (1), customer support systems (2), internal systems (3), then everything else (4) allows the scheduler to ensure all tier 1 system scans execute weekly, threading tier 2 systems biweekly and tier 3 monthly or quarterly depending on load & demand. Generally, the tier 4 systems are such low priority that they can be processed during the day as interactive processes done on request. Normally, these tiers are set by executive management with guidance from the Data Governance Office.
Integration Layer
The rationalization of metadata is done to comply with some predefined standard to support line of business naming conventions. The integration layer addresses the translation of various formats of naming standards and platform specific limitations. In addition, rationalization makes the version of the metadata consistent with a particular standard such as Common Warehouse Metamodel (CWM) or Information Management Metamodel (IMM). However, the rationalization or homogenization of the metadata will result in the loss of detail specific to the platform of origin in most cases. A user will only get the attributes of the item that are true for all item types involved in the metamodel standard.
While this does reduce the detail, rationalization does provide broader visibility to the business user across the enterprise landscape when performing searches or doing analysis. In addition, rationalization brings more content to the lineage view across platforms, and provides greater vision into the impact analysis of change control requests. Rationalization will not provide anything useful for determining redundant data sources, as these tasks are better left to platform-specific metadata resource containers, such as Oracle, Informatica, and Business Objects.
Integration of content that is not supported by the metamodel standard deployed in the organization’s MME is usually handled by post-processing tools. These products are capable of linking conceptual business metadata to the rationalized metamodel item types necessary to provide the connective tissue or vertical lineage desired by the business. Using a post-processing tool will allow the business user to ask the questions at a conceptual level and drill into the logical and physical content to obtain the answers he/she is looking for.
Conclusion
Remember to keep the “Big Picture” in focus while planning the managed metadata environment (MME). Consider all aspects of the enterprise inventory you plan to acquire and the tools and resources necessary to accomplish it. Keep documentation as current as possible and posted to a common area for team reference and review. Always consider the impact of the business perspective on the technical infrastructure as it will change as your MME evolves.
A future article will explore the infrastructure topics and issues surrounding the Repository and Management layers. These layers include databases, batch files, templates and automation of content into the Repository. Additionally, the article will examine security and some operational aspects of the MME Management layer.

