
Data mapping (source-to-target mapping) is an essential activity for all data integration, business intelligence, and analytics initiatives

Introduction
Data mapping is among the most important design steps in data migration, data integration, and business intelligence projects. Mapping source to target data greatly influences project success – perhaps more than any other task. The outcome of the mapping process is a primary tool for communications between project architects, developers, and testers.
Organizations have come a long way from the time when “data mapping” was a dirty word in E-discovery. However, as data becomes more dispersed and voluminous across organizations, having a centralized resource for quickly identifying where certain electronically stored information (ESI) resides is extremely valuable. Integrating data from multiple sources, as in a business intelligence or analytics system, requires robust data mapping from all sources.
Data mapping: the process of creating data element connections between source and target data models. Data mapping is used as the first step for a variety of data movement tasks including:
- Data transformation or data mediation between a data source and a destination
- Consolidation of multiple databases into a single database and identifying redundant columns of data for consolidation or elimination
- Mappings that document the origins of data, the processing paths through which data flows, and the descriptions of the transformations applied to the data along those different paths.
- Specifying business transformation/conversion rules to be applied to source data
- Identification of data relationships as part of data lineage analysis
Data mapping bridges the differences between two systems, or data models, so that when data is moved from a source, it is accurate and usable at the target destination. The contents of a data map are considered a source of business and technical metadata.
Data mapping is the first step in a range of data integration tasks, including data transformation between the source and destination. A data mapping tool connects the distinct applications and governs the way the data from source application will look like when it is mapped to the destination application. It also supports the application of multiple data manipulation functions that are applied to data when it is transformed from source to destination. Along with data, a data mapper should manage the metadata associated with the data (e.g., multiple structured and unstructured files and formats to map the corresponding fields), creating the output in the desired schemas. Thus, the application should support complex data integration tasks.
Data transformations are among the most common problems facing systems integrators as source data is often in an inconsistent format or structure for target systems needing to use that data. This requires development and integration teams to design and implement code for the mapping operations required to convert the data from one form to another (e.g., from one relational database format to another).
A simple example of data mapping is moving the value from a source ‘address’ field in a customer database to a target ‘client address’ field in a sales department database – and changing the target field length and “cleaning” those addresses at the same time.
Data mapping is required at many stages of data integration, data migration, and data warehouse life-cycles. Consequently, data integration professionals and data analysts must learn data mapping to move and test data; often using an ETL (extract, transform, and load) process.
When and How Data Maps Are Used
Data mapping is used for many types of data movement projects. However, all of the tasks fall into one of two categories.
Data migration projects – the process of selecting, preparing, extracting, and transforming data and permanently transferring it from one IT storage system to another
Data integration and conversion projects – combining data residing in different sources and providing users with a unified view in a target system. For data mapping success, an important heuristic is a relationship between the source and the data target – it could be one source to many targets, many sources to one target, or many sources to many targets.
Combined with a well-documented use case describing the need for a map and its intended purpose, heuristics are essential for mapping success. It is imperative that decisions made regarding business rules and map heuristics (chosen approaches) are clearly documented so the evidence is available to describe why each decision was made and by whom. This serves as an audit trail of decisions made during the mapping process.
Mapping development rules must be verifiable to validate mapping(s), regardless of whether it was accomplished by automated or manual means. Assumptions must be used with caution while mapping data; instead, full documentation should be used.
Common Phases for Data Mapping Projects
Step 1: Discover and define data to be moved — including data sets, the fields within each table, and the format of each field after movement. For data integrations, the frequency of data transfer is also defined.
Step 2: Map the data — map source fields to target destination fields
Step 3: Transformation data — when fields require transformations/conversions, formulas or rules are designed and coded
Step 4: Test — using a test system and sample data from sources, run the transfers to see how it all works and make adjustments as necessary
Step 5: Deploy — once it has been determined that data transformations are working as planned, schedule a migration or integration go-live event
Step 6: Maintain and update — for ongoing data integration, data maps will require updates and changes as new data sources are added, as data sources change, or as requirements at the destination change.
Data Maps Described
It should be assumed that source to target mappings are key for any ETL solution. In addition to containing the mapping of fields from sources to targets, data mappings should define the following important basic information. See Figure 1 for a high-level example of information commonly documented a source to target data mapping.
Data modelers, data and business analysts, ETL developers, and testers have a keen interest in…
- Database connections for source and target tables
- Source and target data descriptions – what each data set represents
- Source and target field descriptions – what each field represents
- Examples of field/attribute contents
- Source and target data types, dates, and times (metadata)
- Null, not Null, default indicators
- Transformation, aggregation, enrichment description rules for each field
- Error handling conditions and logic for each record, each field
- Columns participating in referential integrity
- Primary / foreign key columns that assure source records are unique
- How tables are joined (the type of SQL join)
- Slowly changing dimension (SCD) and change data capture (CDC) attributes and logic
- Change and version log entries to describe additions and changes to the mappings
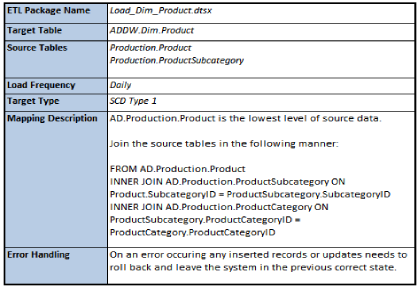
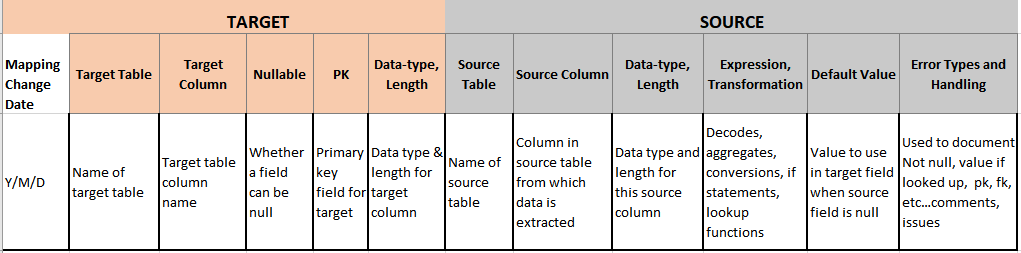
Figure 1:Sample data mapping template
Conclusion
Mapping is always resource-intensive requiring hands-on development, review, and knowledge about all sources and targets. Human intervention is necessary for mapping design and validation of map outcomes. Commercial and open source mapping tools can assist in the process by providing varying degrees of automation. Manual review is required, to a varying extent, to map the portions that failed automated mapping and to validate the results of automated mapping.

