
Metadata infrastructure planning should include all the MME layers while maintaining focus on the objective.
Introduction
It is essential to retain focus on the overall objectives of the organization’s managed metadata environment (MME) to have a successful implementation. Within an MME’s infrastructure, there are six layers, and each layer has specific purposes.
A previous article explained overall MME planning, and gave an overview of the sourcing and integration layers of an MME. This article addresses the repository and metadata management layers of the MME.
Walk the Layers
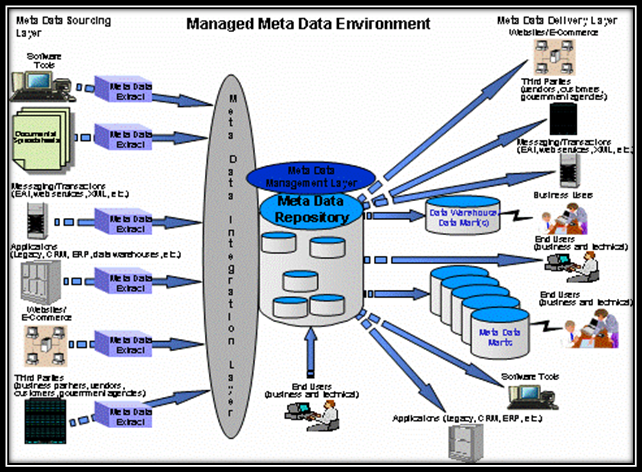
Figure 1: Managed Metadata Environment (MME)
Repository Layer
The repository layer examines the various environments, meta models, extensions and standards that contain the enterprise metadata inventory. The sourcing tools used for the collection of metadata will govern the environmental structure of repositories and the assignment of meta models within each repository. Those meta models and the extensions supporting the integration of business metadata will drive the standards deployed in each repository across the enterprise landscape based on the perspectives necessary to support the organization’s data and metadata requirements.
Source Hosting
The acquisition members of the MME team will require a repository to develop acquisition batching procedures, whether this is a local repository on individual systems or a shared repository on the development platform of the enterprise. These same resources will be developing load procedures for each repository in response to the business and technical perspectives required. For instance, data governance and data stewardship may require working areas for each project that the organization undertakes across the enterprise, and may require a validation area for resolving conflict with discrepancies in terms and definitions among projects or departments.
Environmental Separation
This concept provides separation of environmental layers into individual repositories for Development, Test and Production environments. An organization’s particular situation also may house layers such as Cycle, Unit Test, and System test; and may include replication layers. Some EWSolutions’ clients have been very specific about capturing only production metadata . This insistence does not eliminate any of the repositories needed to provide MME life cycle management, from an infrastructure perspective performance and function. For instance, an organization’s business requirements for data governance and stewardship may add separate repository environments for the management procedures enforced.
There are some products that allow for the layering of content within a single repository; one should consider the impact of such an infrastructure on sourcing, delivery development and integration processes. This capability is important, especially when business perspectives require the rationalization of multiple meta models into a lesser detailed CWM (Common Warehouse Meta model) standard for the purposes of analyzing and visualizing the enterprise landscape for production.
This overview of the business environment would never meet the technical perspective required to analyze the data structures within a platform, since all platforms specific detail has been homogenized and no development or test metadata is persisted in the CWM view. This type of requirement will always drive the need for multiple repositories as will performance demands.
Repository Structures
Each repository will have a specific set of meta models that is provided by the vendor or created by a meta modeler/architect to support the metadata and relationships necessary to provide the perspective required by the delivery interface. Business stewards will want to see metadata specific to the project(s) they are currently assigned, as well as the state of the terms, definitions, rules and formulas submitted for enterprise standard status. Technical stewards will want to see metadata specific to their platform for a given project assignment, as well as the ability to search across platforms for redundant structures or impact analysis issues with data structure attribution.
Separation of Content
Metadata content separation in the infrastructure serves two main purposes:
- To increase performance for the business users by eliminating metadata of no interest
- To isolate load jobs to speed update processes while running multiple job streams against different repositories.
As metadata content within each job stream grows, additional resources can be dedicated to specific repository job streams. Additionally, conflicts in delivery interface specifications can be avoided by isolating the conflicts to a separate repository and web interface, since isolation can permit a change to one interface with no impact on the others and increases the perception of stability.
Management Layer
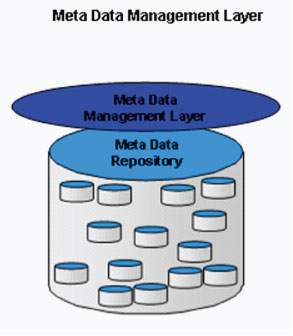
Figure 2: Metadata Management Layer
The management layer handles all aspects of the MME for processes and procedures across all layers. The management layer answers the questions:
- What constitutes the enterprise landscape inventory?
- Who is the point of contact for issue resolution for each layer and who resolves conflict between layers?
- What naming conventions are in effect for each layer?
- What file structures are persisted for each layer?
- Where are the files stored?
- When are files replaced, if ever?
- What is the backup policy?
- What is retention for backups?
- What actions trigger an additional backup action?
- What metrics are maintained across the MME?
- Who collects the data for these metrics and when are they no longer retained?
- Which metrics are shared with repository users?
These and many more processes and procedures are managed in this layer of the MME.
Consider Security
Security policies at most companies require an entire division or multiple departments to administer and manage them, depending on the size of the company. If there are legacy systems, then mainframe security groups are part of the environment. And each distributed platform for UNIX and Windows will certainly have their own security groups as well. In really large organizations, enterprise services might also have security groups, posing their own challenges. There is no “one stop shop” to manage all security access across the enterprise landscape. Much of the access issues will require time and many meetings in order to make clear your intentions for access and the coordination of process ID’s.
Be sure to consider and allocate sufficient time to acquire the required access to all enterprise systems on all platforms and environment layers, not just the one that is the focus of the current project or projects. As a program, the MME will serve many perspectives and will affect everyone in the organization to some extent. Therefore, including the MME in the enterprise security scheme is essential to success.
LDAP Integration
Some organizations are just getting to the point of deploying single sign-on security. Some, if not most, metadata tools support Lightweight Directory Access Protocol (LDAP) integration to some extent. Even if a tool supports LDAP and the organization requires it be used, the repository administrator must determine the level of support to be provided by LDAP for the MME. Is it merely authentication of user id and password, or is it capable of defining privileges for the specific portion of the MME being accessed? If it is not capable of individual privileges and this is a large organization with thousands of users and multiple repositories, management of these security policies will consume resources beyond what most organizations allocate for the tasks.
Consider the security needs of the organization and the MME program early in the process so that resources can be allocated and justified prior to the need for them. And if individual ID’s are required for audit purposes, restrict those accounts to individuals with insert and update privileges.
Roles across the Enterprise
MME security is typically a role-based configuration. To ease that burden, stewards are given the right to update roles and analysts generally end up in default roles that have read-only access. If there is a need to separate update responsibilities among several roles, this scenario allows security administrators to manage the exceptions instead of setting privileges for every new user across all new content.
Using role-based configuration allows an administrator to establish and administer a few dozen user ID’s with update privileges across the MME, making an activity that could take days to update be reduced to a few hours at most.
Privileges by User Groups/Roles
Role based security allows for subject areas to be assigned to a role and any user ID in that role instantly has access to the new subject area.
Non-Person ID (Process ID)
These types of accounts typically are used to run procedures in the production environment on very specific hardware. This allows the individuals responsible for setting up batch processes to have the account and password, but not the access to the environment in which the account will actually operate. These types of accounts are generally difficult to acquire and take some time to negotiate, so planning for these accounts earlier is critical to successful automation processes. Furthermore, keep in mind the number of batch processes that will use these accounts and the password change policy, most organizations will not allow passwords to persist beyond 6 months, even for NPID’s (Non-Person ID).
If an organization has thousands of sources that are scanned into the MME and loaded into as few as three repositories, that would constitute editing 4000 batch files every 6 months, assuming that an administrator can scan an entire server and not individual databases on a server. If servers cannot be scanned this way, then 4000 batch jobs could easily turn into hundreds of jobs per server per environment per tool resulting in 100,000 or more batch edits for the same metadata acquisition and loading.
Operational Metrics
Include the following observations backup durations by environment, storage allocated versus storage consumed by environment, batch job count and durations for acquisition by environment, batch job counts and durations for loading by environment, and job stream durations and object acquisition counts. These operational metric populate the enterprise scorecard providing management with the statistics necessary to manage the MME program.
Metadata Marts
A metadata mart is a database structure, usually sourced from a metadata repository, designed for a homogeneous metadata user group (see Figure 2). “Homogeneous metadata user group” is a fancy term for a group of users with like needs.
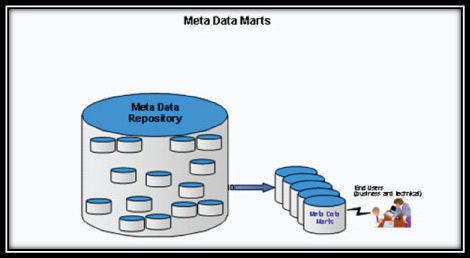
Figure 3: Metadata Marts
There are two reasons why an MME may need to have metadata marts. First, a particular metadata user community may require metadata organized in a manner other than what is in the metadata repository component. Second, an MME with a larger user base often experiences performance problems because of the number of table joins that are required for the metadata reports. In these situations, it is best to create metadata mart(s) targeted specifically to meet those user needs. The metadata marts will not experience the performance degradation because they will be modeled multi-dimensionally. In addition, a separate meta mart provides a buffer layer between the end users the metadata repository. This allows routine maintenance, upgrades, and backup and recovery to the repository without impacting the availability of the metadata mart.
Metadata Delivery Layer
The metadata delivery layer is the sixth and final component of the MME architecture. It delivers the metadata from the metadata repository to the end users and any applications or tools that require metadata feeds to them (Figure 3).
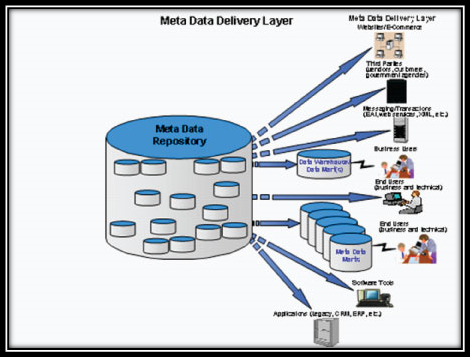
Figure 3: Metadata Delivery Layer
The most common targets that require metadata from the MME are:
- Applications
- Data warehouses and data marts
- End users (business and technical)
- Messaging and transactions
- Metadata marts
- Software tools
- Third parties
- Web sites and e-commerce
Professionals who have built an enterprise metadata repository realize that it is so much more than just a database that holds metadata and pointers to metadata. Rather, it is an entire environment. The purpose of the MME is to illustrate the major architecture components of that managed metadata environment.
Conclusion
As always, keep the “Big Picture” in focus while planning an MME infrastructure. Consider all aspects of the enterprise technical inventory and the tools and resources necessary to accomplish the goals and objectives for the MME. Keep documentation as current as possible and posted to a common area for team reference and review. Always consider the impact of the business perspective on the technical infrastructure as it will change as the MME evolves.

