
Evolutions occur gradually, and the evolution of textual data’s capabilities has shown the value inherent in it, despite the limitations of traditional database management systems
The least obvious time to be aware that you are witnessing an evolution is in the middle of the evolution. Evolutions occur gradually and naturally, to the point that they just seem natural to the witnesses to the evolution.
Among the many evolutions of technology that have occurred and are still occurring today is the evolution of the technological handling of text by technology. Text has always been an uncomfortable fit for database management systems. Database management systems are optimal for storing and managing recurring transactions, such as sales transactions or the recording and managing of ATM transactions. Database management systems work best when there are many records whose structure is identical.
And text just does not fit that description. Text just is not organized into the neat uniform little boxes that other data fits into. But, even from the beginning, it was recognized that there was value in text.
Accordingly there has been an evolution of the treatment of text within the confines of the standard data base management system.
Figure 1 depicts the evolution of textual data.
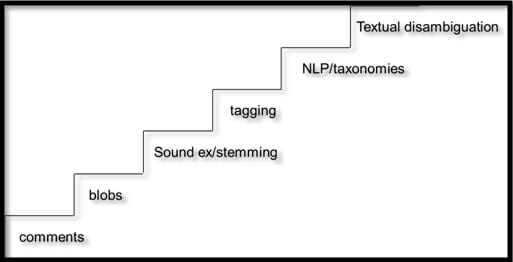
Figure 1: Textual data evolution
THE COMMENTS FIELD
In the beginning text could always be stuffed into a data base attribute affectionately known as the “comments” field. The data base designer created an attribute called comments along with the many other attributes that associated with the data the designer was working on. And the user was free to put anything in the field.
But soon it was recognized that there were problems with the comments field. The first problem was that there was no discipline in the treatment of the field. One person would use comments to describe inventory and the next person would use comments to describe the reaction of a customer. There simply was no uniformity in what people put into the comments field.
The second problem with the comments field was that one person put in 10 bytes of information and the next person put in 10000 bytes of information. This distinct lack of uniformity of size presented all sorts of data management problems to the data base designer.
THE BLOB
The vendors of database management systems decided to address the problem of text. The next step in the evolution of the management of text was the creation of the data attribute type called a blob (binary large object). The blob was designed to accommodate the extreme variability in the size of text that was stored. Indeed the blob did ease some of the problems of data management that faced the designer trying to use comments fields.
But the blob had a problem. Even though text could be stored inside the blob, once stored inside the blob very little if anything could be done with the contents of the blob. So, the blob was a step in the right direction, but only a step.
SOUND EX/STEMMING
The next step in the evolution of textual data management was that of sound ex and stemming. Sound ex was the practice of looking at text and codifying it based on its pronunciation. Stemming was the practice of reducing words to their common Greek or Latin stem. Sound ex and stemming had their uses. But the functionality of sound ex and stemming was limited. In terms of analysis they added very little to the ability to understand text. However they represented the first step in actually being able to go into the blob and start to make sense of the text found inside the blob.
TAGGING
The next step was tagging. In tagging the analyst identified key words (metadata) and went into the blob to find the existence of those key words. This was a greater sophistication that sound ex or stemming. But there were problems with tagging. The first problem was that in order to do tagging the analyst had to know what he/she was looking for before the document was tagged. The second problem was that even upon tagging some words have multiple meanings.
Tagging was definitely a step in the right direction. But it was only a step.
NLP AND TAXONOMIES
The next step in the evolution of textual management was the step of natural language processing (NLP) and taxonomy processing. Natural language processing is the step that recognizes that sentiment analysis can and should be done against text. And one of the most effective tools in the quest to find sentiment was the use of taxonomies. A taxonomy is the classification of words. There are many kinds of taxonomies. And the analyst used taxonomies to sort through text and develop a feeling for the sentiment that was being expressed.
TEXTUAL DISAMBIGUATION
The top of the evolution is the step of textual disambiguation (sometimes called textual extraction / transformation / loading – ETL.) Textual disambiguation recognizes that much more then sentiment analysis can be done with text. In addition textual disambiguation recognizes that – as important as taxonomies are – there is more to reading and analyzing text than classifying text.
In addition textual disambiguation recognizes that in order to be effective that the results of textual disambiguation processing need to be visualized.
Does the processing of text stop with textual disambiguation? Undoubtedly the answer to that question is no. Textual disambiguation is merely the next step in the evolution of processing text. Future years will see textual disambiguation unfold into something else more sophisticated.

