Introduction
In several surveys, taken by various research organizations about master data management and data quality, on average, 83% of respondents reported that their organizations have suffered problems due to poor master data. Business trends such as the ever-increasing volume of data, the need to comply with regulations, and the drive to deliver timely and accurate business reports have driven the desire for organizations to take a hard look at the best ways to improve data quality.
Moreover, attention to data quality can show many advantages, for all data management professionals. Improvement to data quality can mean more accurate reporting, better segmentation, and marketing to customers, more accurate inventory systems, and improved manufacturing processes, to name just a few benefits. Not only does attention to data prevent loss, but there is potential for huge revenue gains as well. For all organizations, there is clearly a relationship between the quality of data and the efficiency of business processes.
Yet despite the potential benefits of data quality, there are still common misconceptions about what data quality is and how to go about improving corporate information and its management.
Myth One: Data Quality Is Not My Problem
For almost any company, non-profit or government organization in the world, it is safe to say that the power of data quality should be recognized from the top and propagated throughout the organization.
All members of an organization are either producers of data, or users of data, or both. All users have an impact on organizational information. A call center worker answers the phone and enters data, a marketing professional sends an e-mail blast and uses data, and an executive relies upon business intelligence from a report that uses data.
Data is the lifeblood of information that flows throughout an organization to connect everyone and the entire company needs to pay attention to managing it. Technologists often fight the myth that data quality is an IT problem, although thankfully that myth is dying in popularity. Still, there are likely people in most organizations who will not admit the impact they have on the integrity of data. Continual education about the benefit of maintaining data quality should be a management mandate. Company leaders must remember not to relegate the task of data quality to the IT staff. Just like the microwave in the lunch room, everyone uses data and must do their part to keep it clean.

Figure 1: Data Quality Definition
Myth Two: I Can Fix the Data Myself
When problems with data quality are discovered to be affecting business efficiency, don’t believe that one person can solve the corporate data quality problem individually. Corporations need to rely heavily on cross-functional teams to understand the meaning of the data and its impact on the organization.
The science of hermeneutics is very much alive in the world of data quality, which necessitates that the company consider both the syntax of the data and the semantic meaning of the data. A part number in a database might have the correct number of digits and format (syntax) but may be no corresponding part in your inventory (semantic). Consider, for example, the simple two-letter abbreviation “pt.” Within various contexts, “pt” can mean many different things:
- PT Emp = Part-time employee
- PTCRSR = PT Cruiser (Personal Transportation Cruiser)
- Blk pt chassis = Black platinum chassis
- 24pt bk = Manual published in 24-point type
- 2 pt asbl = Two-part assembly
- 1 pt = One pint
- LIS PT = Lisbon, Portugal
Data quality requires business people and IT people working together to understand the meaning of data like PT. The only way to make the data fit-for-use is to provide context, also known as metadata.
Myth Three: Fixing Data Quality Issues is Easy
On the surface, data quality appears to be a relatively easy problem to solve for SQL programmers. They may be tempted to write some custom scripts to profile the data and more scripts to sort it all out.
A common approach to improve data is to create custom code during a data transformation process. At first, this approach may have some success. However, it is the long-term impact that is the deadly aspect of this myth. Eventually, managing the custom code leads to the need to hire more and more resources to code, debug and revise the custom solution. Enterprises that choose this as a long-term strategy will run into ever-rising development costs and schedule overruns. The process of writing a custom data quality solution can incur additional costs if the project leader decides to leave the company, since much of the process and knowledge of the code may reside inside their head.
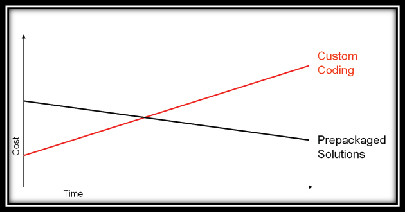
Figure 2: Costs and Time – Custom Coding vs. Packed Solutions
A data quality process must be proven, reproducible, and most of all transparent in order to achieve the highest efficiency and biggest benefit. That is why many successful project managers turn to the enterprise software vendors where the processes have been proven and can be easily reproduced across the company. Although it may be a little more expensive to start the project using an off-the-shelf solution, some find it more efficient to leverage the proven processes from others in the same industry. Software automation of data quality processes provides the speed, accuracy, transparency and scalability that organizations need to go enterprise-wide.
Myth Four: Our Data is Good
If the data works well in the source system, conventional wisdom would indicate that it would work in target systems. This too is a myth that organizations need to understand. Data that is “fit-for-use” is an important concept to grasp for anyone involved in a data migration. The source systems may serve a single purpose that has less stringent data quality requirements. The unfit source system data works perfectly because special routines may be written into the source systems applications to handle data anomalies. The data model of any source system defines which data goes in what buckets, but a common data anomaly is a broken data model.
It is common to find tax ID numbers (social security numbers) in a name field, delivery information in an address, or certain flags in a date field, to name just a few examples. The source application will understand the rule exceptions, but the target application will not. When data migrates to a new system, the special routines are lost, thereby causing data that does not load properly, compounded inaccuracies, time and cost overruns and, in extreme cases, late-stage project cancellations.
Tackling these types of data quality problems after the data is already loaded and operational is more difficult. When issues are identified, organizations will often undertake measures to rectify the problems, but all too often, these efforts are shortsighted and only work to extinguish the fires.
The tactic to fight this issue is not to assume that the data model is accurate. Do not assume that the FNAME attribute contains all first names or that the EXPDATE attribute contains all expiration dates. The best practice is to profile the data very early in the data migration process to completely understand the data quality challenges and ensure that there are no outliers. By profiling early, any major challenge with the data can be built into a more accurate project plan.
Myth Five: Once Our Data is Clean, It Is Clean
In accounting, the “going concern assumption” is the assumption that a company will continue to function as a business, now and into the future. In business, it is also important to think about the going concern of the organization’s information. Do the people, processes and technologies that have been established provide a strong foundation for the future of the corporation? Are they created with a vision of hope and prosperity?
Data quality is not a one-time “fix it and forget it” project for the IT department. Rather the process of building a framework for capturing, consolidating, and controlling data quality is most likely to be an evolutionary one that occurs over time and involves business users throughout the organization.
Focus on reusable, portable components to economically and incrementally build better data quality across the organization, establish automatic rules-based processing for analyzing, harmonizing, and maintaining data and expand and grow data quality practices over time.
Myth Six: Business Units Should All Try to Fix Data Independently
Is the company working across business units to work toward separate data governance, or is data quality done in silos? To provide the utmost efficiency, information quality processes should be reusable and implemented in similar manner across business units. This is done for exactly the same reason the organization might standardize on a type of desktop computer or software package for your business – it is more efficient to share training resources and support to work better as a team. Taking successful processes from one business unit and extending them to others is often the best strategy.
The most common project for cross-business unit data is the definition of a customer. In other words, problems come in deciding what a customer is. Accounting may judge the suitability of a customer by its ability to bill. Marketing may judge a customer by the ability to send snail mail, e-mail and perhaps even social media information. It may be important for some business units to distinguish the two customers that might be found in name data like “George and Mary Jones”, while it may not be as important for other business units.
Similar data models must be defined and implemented by the corporation for the definition of a product, a part in inventory, an employee, a brand, an order and more. If the goal is to have a single golden source of data, or master data, the definition is very important. The definition should be defined, maintained, and upheld across all of the enterprise’s business units. This action is part of a unified approach to data governance, and serves as a rationale for making data governance an enterprise function.
Conclusion
It is important for all professionals to manage data properly and work to secure high data quality. The digital universe continues to expand. With these continually increasing data volumes, it is more important than ever to refute the data myths, and manage data quality, starting with the places where data is entered and continuing through to its use throughout the corporation. Educating the entire company about the depth of the problem, focusing on data’s impact and how corporate citizens can participate is the best way to deliver a brighter future for every organization.


